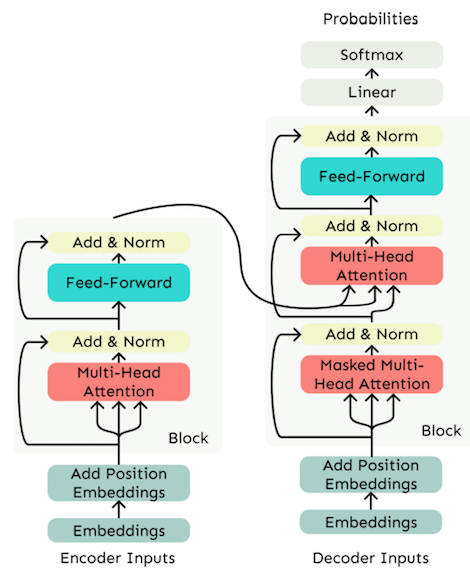
# 自注意力机制(Self-Attention)
# 基础原理
自注意力机制通过计算序列中不同位置之间的相似度(attention),来生成每个位置的加权表示。
-
查询、键和值(Query, Key, Value)
首先,对输入序列中的每个词向量 xi,通过三个可学习的权重矩阵 WQ,WK,WV 得到其对应的查询向量 qi、键向量 ki 和值向量 vi。
qi=WQxi,ki=WKxi,vi=WVxi
-
相似度计算与权重归一化
通过计算查询向量 qi 与所有键向量 kj 的点积,得到它们之间的相似度 eij。接着,使用 Softmax 函数 对这些相似度进行归一化,使其和为 1,得到注意力权重 αij。
eij=qiTkjαij=∑kexp(eik)exp(eij)
Softmax 函数确保了每个查询向量 qi 对应的所有键向量 kj 的权重之和为 1。
-
加权求和
最后,将所有值向量 vj 按其对应的注意力权重 αij 进行加权求和,得到最终的输出向量 yi。
yi=j∑αijvj
# 矩阵形式
为了实现并行计算,自注意力机制可以采用矩阵形式表示,对整个序列进行批量处理。
设输入序列 X 是一个 n×d 的矩阵,其中 n 是序列长度,d 是词向量维度。
X=[x1x2⋯xn]T
通过权重矩阵 WQ,WK,WV,一次性计算出所有查询矩阵 Q、键矩阵 K 和值矩阵 V。
Q=XWQ,K=XWK,V=XWV
注意力矩阵 QKT 的每一行代表一个 qi 与所有 kj 的相似度。
最终的输出矩阵 Z 通过 Softmax 函数对 QKT 的每一行进行归一化,并乘以 V 得到。
Z=softmax(QKT+mask)V
注意:这里的 Softmax 是对 QKT 矩阵的每一行进行操作的。
# 编码序列顺序:位置编码(Position Encoding)
Transformer 不具备处理序列顺序的能力,因此需要引入位置信息。通过将位置向量 pi 与词向量 xi 相加,将位置信息融入到输入中。
x~i=xi+pi
有两种常见的位置编码方式:
-
基于正弦函数的固定位置编码
这种方法使用正弦和余弦函数来生成位置向量,其周期性允许模型处理比训练时更长的序列。然而,这种编码是不可学习的,其外推性表现不够优秀。
pi=sin(i/100002∗1/d)cos(i/100002∗1/d)⋮sin(i/100002∗2d/d)cos(i/100002∗2d/d)
-
可学习的绝对位置编码
这种方法直接将位置编码作为可学习的参数。模型可以学习每个位置的最优表示,从而具备更大的灵活性。然而,这种编码不能外推到训练数据范围之外的索引。
它通过学习一个矩阵 P∈Rn×d 来实现,其中每一列 pi 都是可学习的参数。
# 结构与细节
# 多头注意力(Multi-Head Attention)
多头注意力通过使用多组不同的权重矩阵 (WQ,WK,WV) 并行计算多组注意力,从而使模型可以从不同的“表示子空间”中学习到多种注意力权重,更全面地捕捉不同位置的信息。
-
并行计算
为每个头 l 定义一组独立的权重矩阵 WlQ,WlK,WlV∈Rd×hd,其中 h 是头的数量。
Ql=XWlQ,Kl=XWlK,Vl=XWlV
每个头生成一个输出矩阵 Zl。
Zl=softmax(d/hQlKlT)Vl∈Rn×hd
这里引入了缩放因子,详见下一节。
-
拼接与线性变换
将所有头的输出矩阵 Z1,…,Zh 拼接起来,并通过一个最终的权重矩阵 WO 进行线性变换,得到最终的输出。
Z=Concat(Z1,Z2,⋯,Zh)WO∈Rn×d
# 缩放点积(Scaled Dot Product)
当向量维度 d 较大时,点积 QKT 的值会变大,导致 Softmax 函数的输出值趋于极端(0 或 1),从而使得梯度变得非常小,影响模型训练。为了解决这个问题,需要对点积结果进行缩放,通常除以 dk,其中 dk 是键向量的维度。
Zl=softmax(d/hQlKlT)Vl
# 解码器屏蔽(Masking)
在解码器中,为了防止模型在预测当前位置的词时“看到”未来位置的信息,需要对注意力矩阵进行屏蔽。这通过将注意力矩阵的右上角元素设置为 −∞ 来实现,经过 Softmax 后,对应的值将变为 0。
Mij={−∞,1,if j>iotherwise
Z=softmax(QKT⊙M)V
这里的 ⊙ 表示元素级乘法。
# 前馈网络(Feed-Forward Network)
在注意力层之后,Transformer 为每个位置的输出向量添加一个前馈网络,进行非线性后处理。这个前馈网络由两个线性层和一个 ReLU 激活函数构成。
FFN(x)=ReLU(W2ReLU(W1x+b1)+b2)
# 残差连接和层归一化(Add & Norm)
每个子层(自注意力层和前馈网络)的输出都伴随着残差连接和层归一化。
- 残差连接:将子层的输入与输出相加,有助于解决梯度消失问题,使网络可以训练得更深。
X(i)=X(i−1)+Layer(X(i−1))
- 层归一化(Layer Norm):对单个样本的所有元素进行归一化。
LayerNorm(X)=σ+ϵX−μ∗γ+β
与批归一化不同,层归一化对序列长度乘以特征维度的矩阵进行归一化,而批归一化对序列长度乘以批次大小的矩阵进行。由于批归一化不适用于可变长度序列,层归一化是处理变长序列的更优选择。
Transformer 采用编码器-解码器的 seq2seq 范式,主要由堆叠的编码器和解码器层组成。
- 编码器:处理源序列,是一个双向模型,可以同时获取上下文信息。
- 解码器:处理目标序列,是一个单向模型,在生成每个词时只依赖于其前面的词。